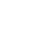前言。
前两篇文章主要讲的是stable diffusion中text prompt转换成。conditioning。还有Noise pridictor消费过程,然后我们讨论了前向扩散和反向扩散去噪的过程。所以趁热打铁只想从更详细的角度,让我们对stable有一个深入的了解 diffusion的工作流程。
工作流程。
许多stable 在diffusion教程中,大家都会看到这张非常“晦涩”的流程图。
当我第一次看到它时,我直呼“看不懂”。经过一段时间的学习,,知识碎片与流程图的每个模块相呼应。
conditioning。
流程图最右侧的conditioningtextt,包含文生图,包含文生图。 imagesprompt和图生图。text clip将prompt转换为conditioning&xff0c;然后进入Noise pridictor。

图中VAE解码器(图片;流程图左侧ε)转换成latent image,与text prompt和contronet生成的depth map,作为conditioning进入Noise pridictor。
#xff08正向扩散;加噪)
同时,stable diffusion将生成噪声图作为“基图”。文生图将seed设置为-1,然后随机生成噪声图。图中将您输入的图片添加噪音,最后生成噪声图。

加噪过程称为正向扩散(forward diffusion),也就是流程图顶部的diffusion process。所以,如何根据这个“基图”生成最后一张图片?
#xff08反向扩散;去噪)
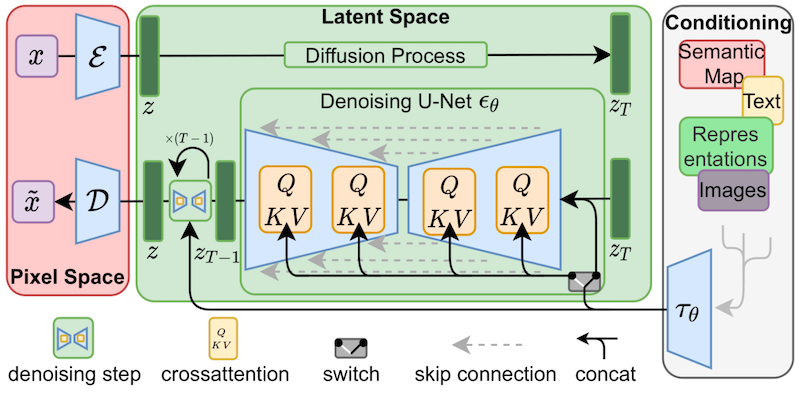
Noise中的噪声图 在pridictor中,我们的目标图片是通过逆向扩散一步一步生成的。
所以,噪声图是如何结合我们输入的prompt和image等conditioning,一步一步地生成清晰的图片
1. cross attention。
conditioning进入Noisening pridictor后,cross会被cross attention(交叉注意力)机制消费控制文本信息和图像信息的集成和交互。cross attention,conditioning与图片相遇༌换句话说,xff00c;就是控制Noise pridictor将噪声图中的某一块,对应conditioning表达的特定信息。
同时,cross attention帮助我们找到高度接触的对象。例如:让我们以“蓝眼睛的男人”prompt为例,cross attention将“蓝”和“眼睛”这两个词搭配在一起,这样,它就产生了一个有蓝眼睛的男人,而不是穿蓝衬衫的男人。
从流程图可以看出在U-Net(Noise pridictor)去噪(denoising)在过程中c;cross attention与conditioning融合后,开始迭代去噪这一除噪过程称为采样(Sampling)。
2. 采样(Sampling)
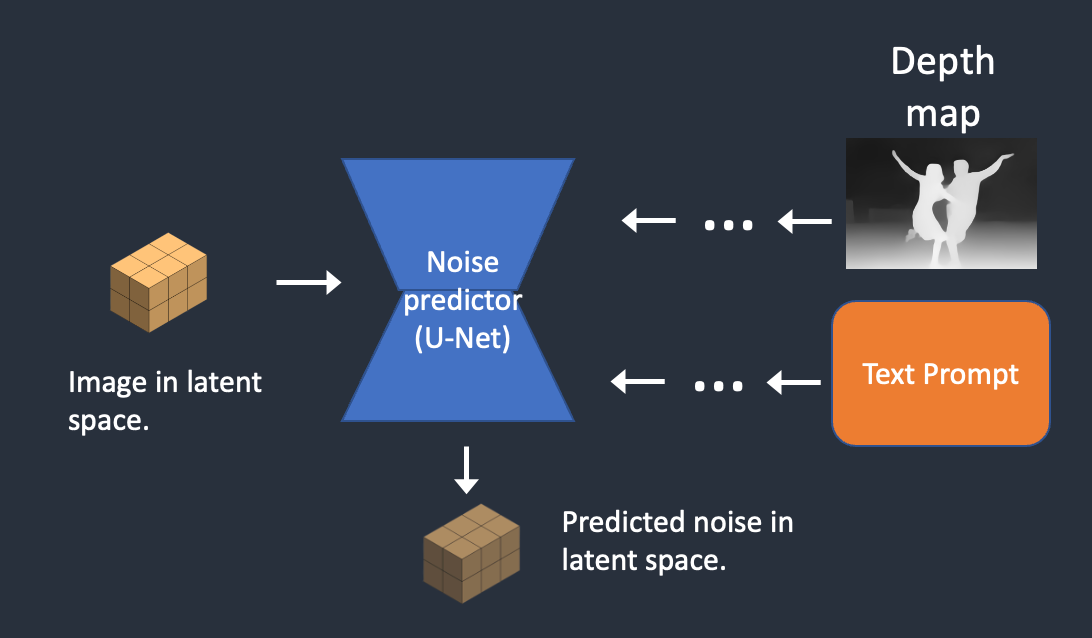
还记得之前说过Noiseeee吗? predictor的作用?Noise predictor用于估计添加到每个step上。总噪声。,Noise从正向扩散获得的噪声图中减去 噪声,predictor预测c;我得到了我们想要的照片。
不可能一步到位预测噪声直接从原噪声图减去c;这种误差很高。因此,需要设置采样步数(sampling step),每一步都会分布预测到的总噪声,生成。noise schedule。,根据noise进行每一步采样 schedule(#xff09噪声计划;减去相应的noise。
当我们将采样步数设置为15时时c;noise的生成 schedule:
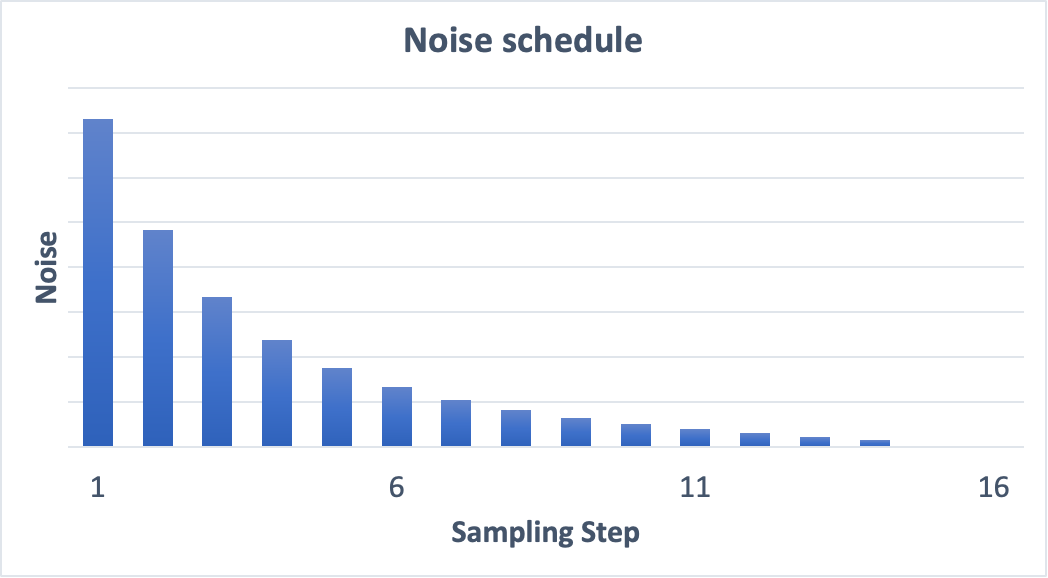
当我们将采样步数设置为30时时c;noise的生成 schedule:
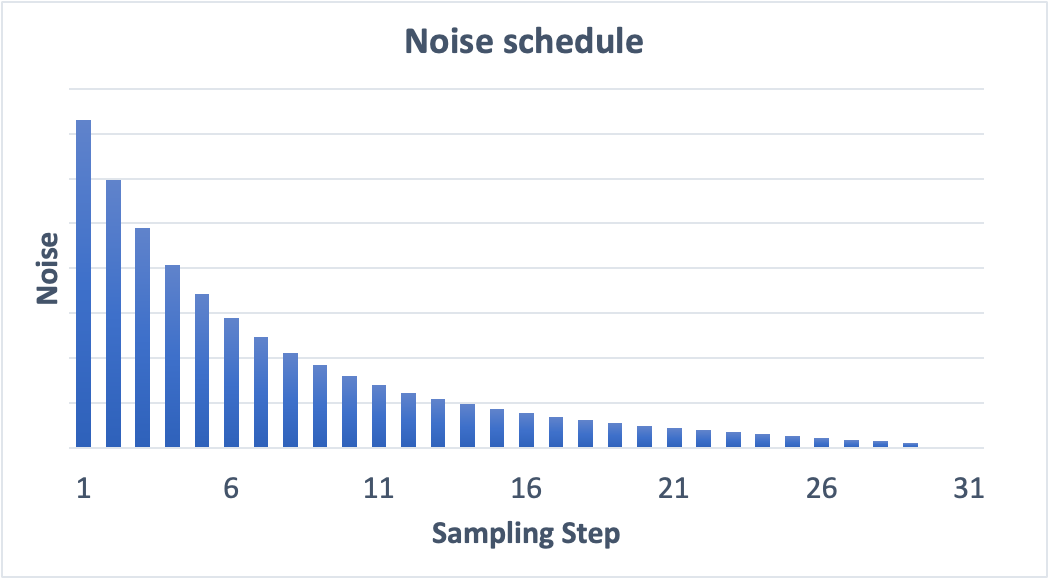
从以上两张图片的对比可以看出每一步减去的noise都是递减的,step越大,noise schedule的下降趋势越平稳c;也说明noise在每个相邻的两个step之间的下降幅度越小,最终映射到结果图片的表现是:图片更符合预期。。
使用相同的text prompt、seed,step分别为10、20、25、在30的情况下生成图片。
Street,cherry tree,train front in the middle of street,railway,spring,pink,outdoor,Vista,Sun,breeze,petals,illustration style,Shinkai Makoto style,Ultra High resolution,4k,你可以看到,step10点,prompt提到的火车没有出现在图片中c;当step为20时时c;火车已经出现在图片中。再看step25和30小时,细节描绘更详细,但总的来说差别不大。甚至在30 step时,prompt中提到的“街道中央火车”,还没有20 step生成更准确。所以说,step也不是设置越大越好。
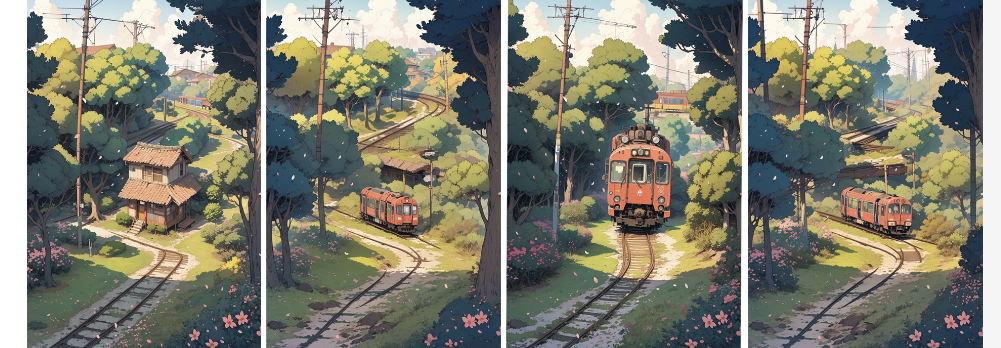
3. 采样器(Sampling method)
所以,谁来遵循noise? schedule采样?Sampling method,它被称为采样方法或采样器。不同的采样器,在相同的条件下,生成的图片是不同的。
在stable diffusion中提供了许多采样器。
当我学习这些采样器时,,首先对采样器进行分类,然后整理每个采样器的特点和使用场景,形成笔记。最后在实践中发现了这么多东西,脑子里根本记不住。因此,我在实践中总结了:最常用的采样器是。

Euler a。、*DPM++ 2M Karras、DPM++ 2M/3M SDE Karras,基本上了解其他的就可以了。Euler:采样器最简单。
- 祖先采样器:后面有a,它们是随机采样器,由于采样结果具有一定的随机性。
- DPM++ 2M Karra:适用于快速、融合、新、优质的东西。
- DPM++ 2M/3M SDE Karras:在很少的步数下生成高质量的图片。
- 以下是使用相同的texttt prompt,20采样步长,分别使用Euler、DPM++ 2M Karras、DPM++ 3M SDE Karas生成图片。
你可以看到�在没有像素放大的图片中,DPM++ 3M SDE Karras生成的图片是最好的细节,但不收敛,随着步数的变化,图像会大幅波动,类似祖先采样器。如果考虑收敛性,选择DPMƱ+ 2M Karras。如果你喜欢稳定和可再现的图像,不要使用任何祖先采样器。

以下是使用相同的texttt prompt,分别使用Euler a和DPM++ 2M Karras生成图片观察它的收敛性。事实上,在生成过程中,step观察的收敛性更直观,但是stable diffusion 不能在webui中实现因此,在结果图片中观察。
text prompt:
A female elementary school student in a sci-fi and futuristic world of the city,Hayao Miyazaki style,manga,2d,colorful.raincoat,pop style,glowing。
使用Euler a生成六张图片:
使用DPM++ 2M Karras生成六张图片,#xff1a;

DPMƱ+ 2M Karras生成的六张图片相似度较高。但是在使用别人的大模型时,建议使用采样器,所以没必要担心这一点。

生成图片。
采样器逐步迭代采样后,基于噪声图去除噪声,最终生成图片此时的图片仍在latenttent中 在space中c;而且我们只能用肉眼看到像素空间(pixel space)图片,因此,VEA编码器( 图中�#;)转换完成c;最终输出图片。
结语。
到目前为止,整个stable diffusion生成图片的过程完成了,使用所学的clip、vae、采样器组件及正向扩散、逆向扩散、采样原理等知识碎片,映射后的流程图,发现柳哑花明又一村。